自社ウェブサイトからデータをスクレイピング
Yext Crawlerは、指定したドメイン、ページやドメイン内のサブページのセットからHTMLやPDFファイルコンテンツをスクレイピングできるため、CMSに取り込むべきコンテンツを正確に制御できます。ウェブサイトのデータが継続的に変更される場合は、スケジュールに従ってクロールが実行されるように構成します。また、1回のみ遡及修正が必要な場合は、1回だけクロールすることもできます。特定のページのセットをクロールしたくない場合は、不要なURLを簡単にブラックリストに登録してクローラーがスキップするよう設定できます。
クローラーを構成
クローラーがウェブサイトをスクレイピングすると、コネクターが未加工のHTMLをエンティティのコンテンツに変換して構造化します。高度にカスタマイズ可能な設定で必要なデータを正確に抽出できます。組み込みのセレクターは、CSSセレクターやXPathセレクターに基づいたターゲットパスの指定や、ページタイトルや本文などの一般的に抽出されるデータタイプのキャプチャに使用できます。コネクターは、テキスト、HTML、URL、画像などを抽出できます。コネクターとクローラーの連携についてはこちらを参照してください。
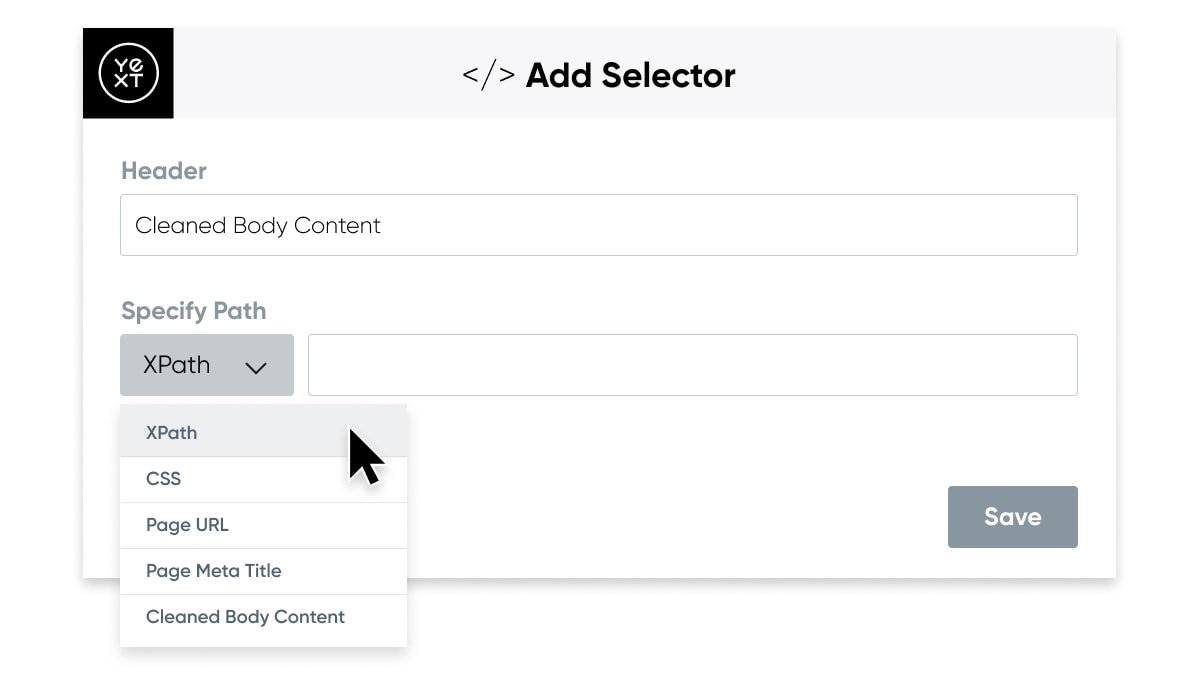
データを変換
ウェブサイト上のデータは、CMSに適した形でフォーマットされていない可能性があります。コネクターの変換を使用して、クローラーの収集したデータをContentに取り込む前に操作できます。コネクターを使用すると、データへの変更をリアルタイムでプレビューして、最大限の精度を確保できます。変換を使用すると、不要な文字の削除、大文字と小文字の区別、テキストの検索と置換、日付の書式設定などを行えます。