非構造化データを検索
検索においては、ユーザーの質問に対する答えをできるだけシームレスに取得することが目標となりますが、問題は、データがバラバラの構造に存在することです。CMS内で高度に構造化されたデータや、半構造化されたFAQなどのデータもあれば、ブログ、ヘルプ記事、ウェブページなど、完全に構造化されていないデータもあります。ドキュメント検索は、顧客に回答を提供できるよう、長文ドキュメントの検索に特に最適化されたアルゴリズムです。

ファイルに保存されているコンテンツを表示
ドキュメント検索では、ファイル内の非構造化コンテンツ(PDF、パワーポイント、ドキュメント内の単語)にインデックスを付け、クエリに対応して関連する結果やスニペットを表示することができます。テキストを抽出してエンティティ上の個別のフィールドとして保存するのではなく、ファイル全体をYext Contentに保存したい場合に柔軟に使える機能です。
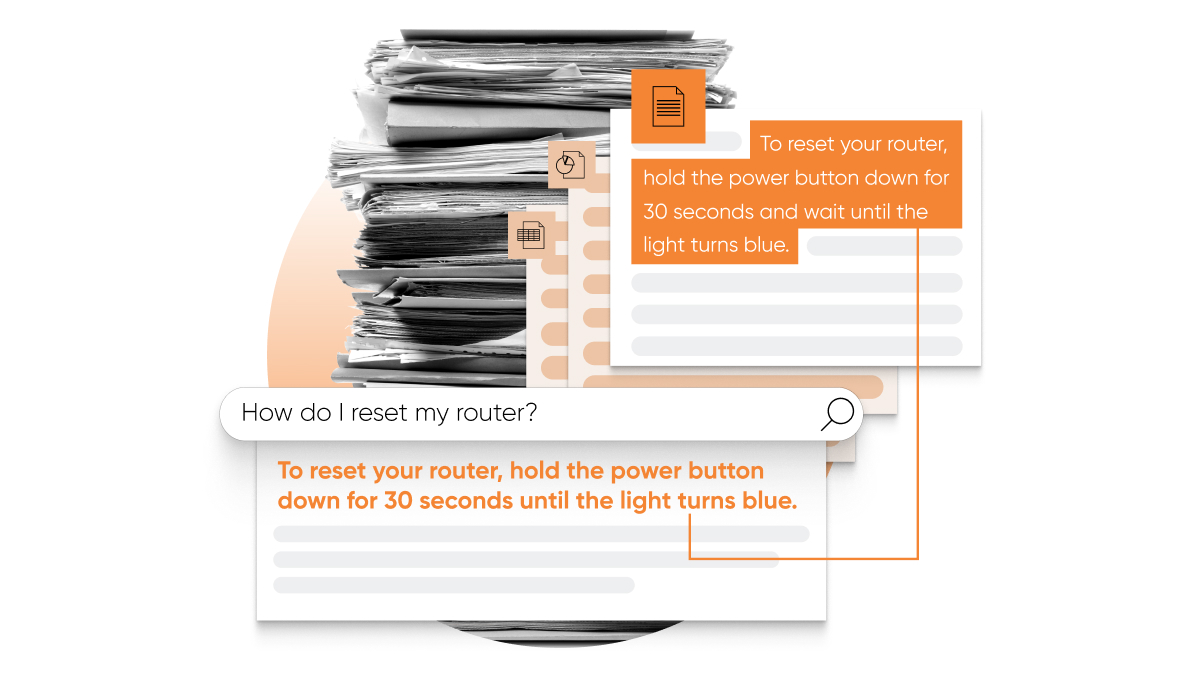
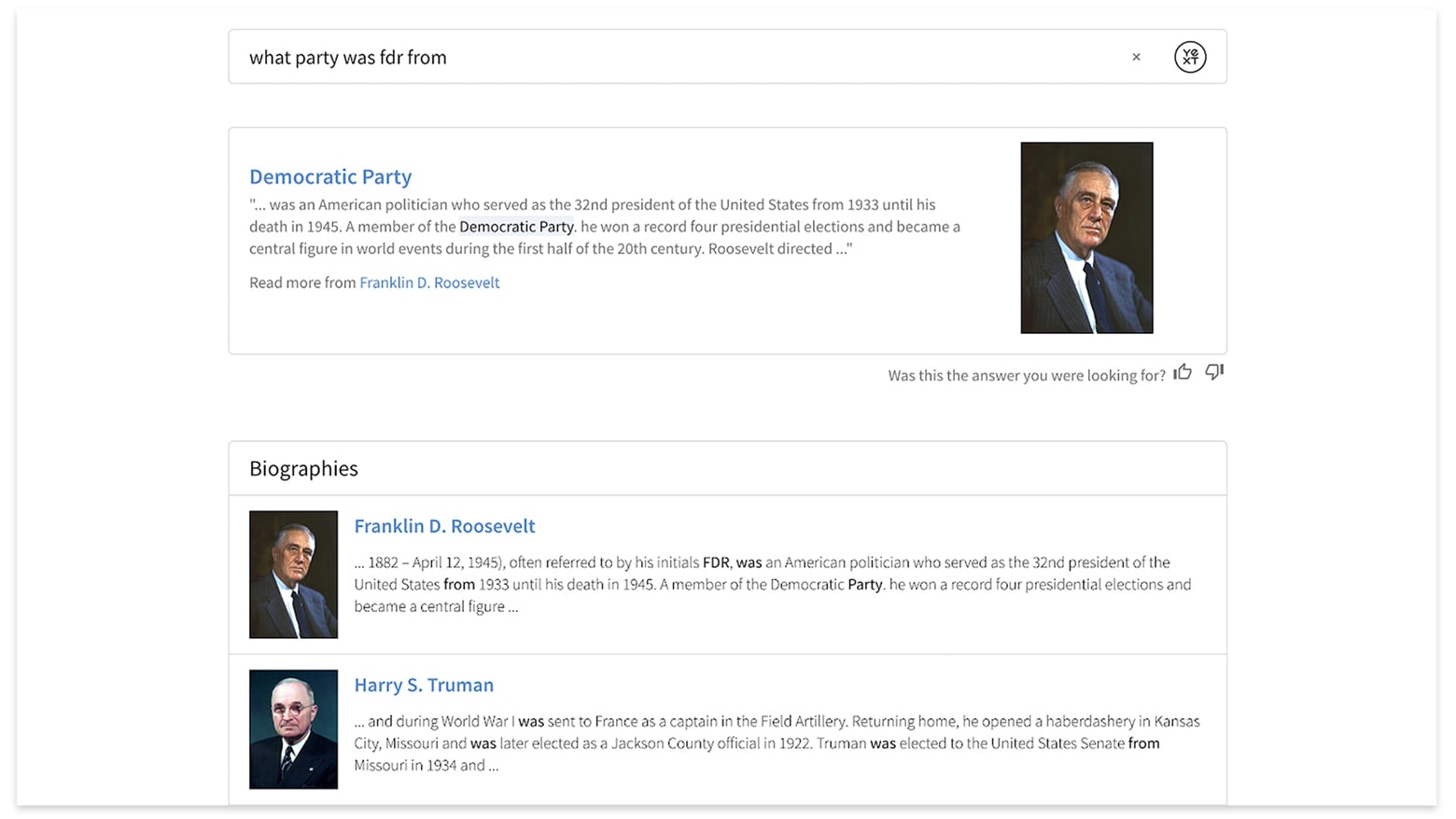
Extractive QAを使用して直接的な回答を提供
Extractive QAは、Searchアルゴリズムの他の多くの側面と同様に、言語を理解するよう訓練されたGoogleのオープンソースニューラルネットワークBERTを使用します。Extractive QAでは、特別にトレーニングされたバージョンのBERTが、長文の文書からユーザーの質問に最適な抜粋を特定します。テキスト内で適切な回答が見つかった場合、アルゴリズムはそれを強調スニペットとして表示します。
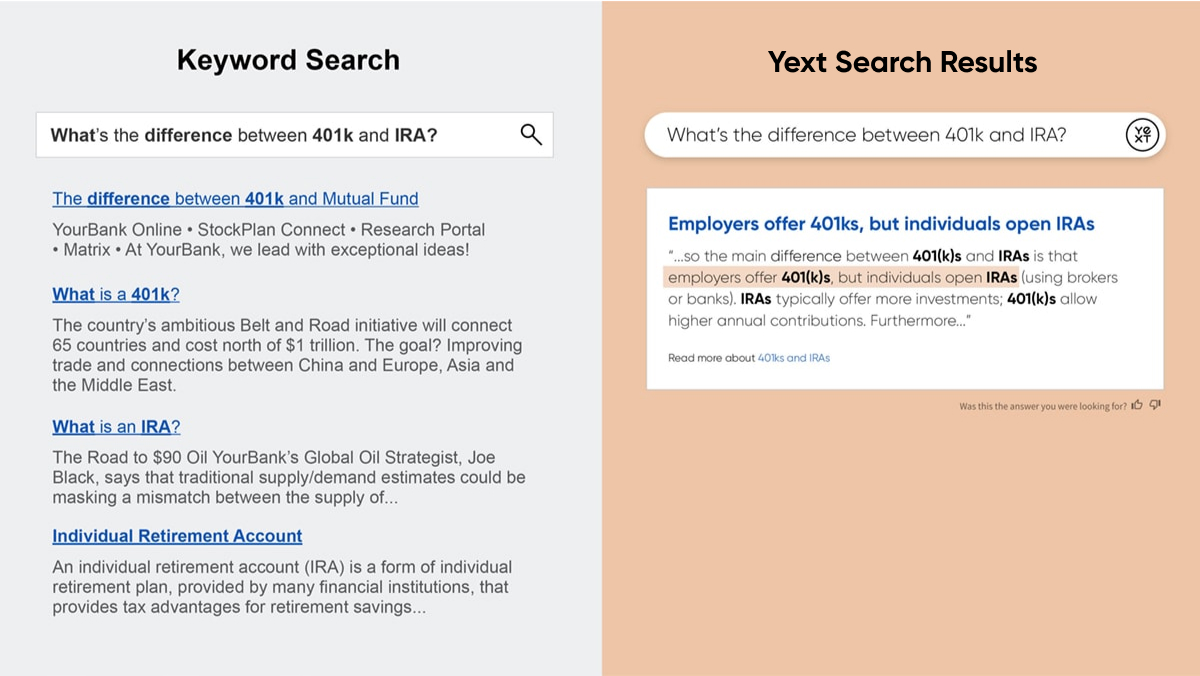
インラインスニペット
Extractive QAは、ページ上部に直接的な回答を提供するだけでなく、ページの下の各検索結果に関連するコンテキストをインラインスニペットとして強調表示します。これらのスニペットは優れた検索エクスペリエンスを提供し、検索者がクエリに対する最適な回答をスピーディに見つけるのに役立ちます。
コネクターで非構造化データを取り込み
非構造化データはさまざまな環境やサイトに存在します。ブログ、サポートサイト、プレスリリースハブなどの場所には、最新の検索向けに設定されていない優れたコンテンツが大量にホストされている場合があります。YextクローラーやZendeskコネクターなどのコネクターを使用すると、アプリやウェブサイトなどのソースから長文形式の非構造化データを取得し、これを活用してCMSを構築し、Searchを強化できます。