Crawler
Crawler
To build a powerful CMS, you need data from all over. One great source of content is your own website. The Crawler scrapes the underlying content on your website, which our Connectors can then turn into structured data for your CMS in just a few clicks. With highly customizable configuration options, the crawler will pull the exact information you want from your website — even text from PDF files you store online — saving you time and expanding your data source options.
Scrape Data from Your Website
The Yext Crawler can scrape your HTML and/or PDF file content from a specified set of domains, pages, or sub-pages under a domain, giving you control over exactly which content is brought into your CMS. If your website data changes consistently, configure crawls to run on schedule, or, if you just need a one time backfill, crawl once. Don't want to crawl a specific set of pages? Easily blacklist unwanted URLs for the crawler to skip.
Configure a Crawler
Once your crawler scrapes your website, a Connector converts and structures the raw HTML into content for entities. Highly customizable configuration allows you to extract exactly the data you need. You can specify a target path based on CSS or XPath selectors or use built-in selectors to capture commonly extracted data types, like Page Title and Body Content. Connectors can extract Text, HTML, URLs, Images, and more. Learn more about Connectors and The Crawler working together here.
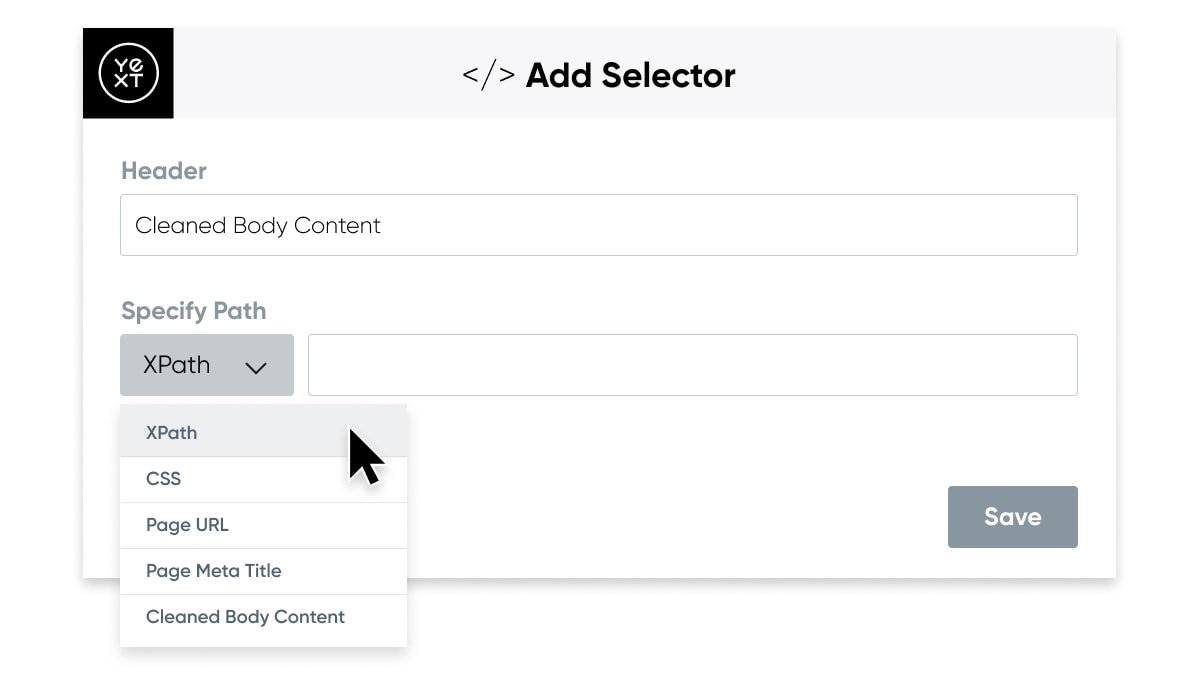
Transform Your Data
The data on your website might not be formatted exactly how you want it in your CMS. Use transforms in Connectors to manipulate data scraped by the Crawler before it enters Content. Connectors allow you to preview any changes to your data in real time to ensure maximum accuracy. With transforms, you can remove unwanted characters, fix capitalization, find and replace text, format dates, and more.

Explore Related Features
Explore Related Features