AI Citation Behavior Across Models: Evidence from 17.2 Million Citations
Each AI Model Cites Differently. That Matters More Than Most Businesses Realize.
Executive Summary
When consumers ask an AI model about a business, the answer they get depends heavily on which model they ask. Not because the models know different things, but because they pull from different types of sources, at different rates, in patterns that vary by industry.
Our analysis of 17.2 million distinct AI citations across Q4 2025 reveals that citation behavior follows predictable, model-specific patterns. This research builds on past work from 2025 where we evaluated 6.9 million citations and developed our location-context framework.
Three findings stand out:
-
Citation patterns vary more within sectors than across them. Restaurants and Specialty Food & Cafes sit in the same sector (Food & Beverage) but show meaningfully different citation profiles. Sector-only analysis often miss this.
-
Claude relies on user-generated content far more than other models. Limited Control citations (reviews, social media) run at rates 2-4x higher than competing models across all seven sectors we studied. This isn't a fluke in one category. It's consistent.
-
SearchGPT treats hotel websites very differently. SearchGPT cites official hotel websites at 38.1%, while competing models range from 16.7% to 22.4%. This is the largest single-model divergence we observed in any sector.
The practical implication is that there is no single "AI optimization" strategy. The source mix that makes a brand visible in Gemini is not the same mix that makes it visible in Claude. Businesses treating AI search as a monolith are optimizing for an average that doesn't exist.
Introduction
Our recent "Rise of AI Search Archetypes" study, a global survey of 2,237 consumers across the U.S., U.K., France, and Germany found that 75% percent of consumers now use AI tools more than they did a year ago, and nearly half use AI search daily.
The shift matters because AI search works differently than traditional search. In traditional search, brands compete for ranking positions on a results page. In AI search, the model synthesizes an answer and cites its sources. Visibility depends on being cited, not ranked. And as this research shows, different models cite different sources.
This creates a problem that most businesses haven't fully grasped. A brand might have excellent visibility in Gemini (which leans heavily on first-party websites) and be nearly invisible in Claude (which draws more from reviews and social content). The brand's "AI search strategy" might be working perfectly for one model and failing for another, and the brand would have no way of knowing without model-level data.
This research examines how the big-four AI models source their citations, what patterns emerge across seven sectors and dozens of industries, and where the gaps between models are large enough to matter.

Methodology
Citation Data Collection
This analysis examines 17.2 million distinct AI citations gathered globally during Q4 2025 across four major AI models. Data was collected using the Yext Scout platform.
Queries were structured to test four intent quadrants: branded objective, branded subjective, unbranded objective, and unbranded subjective. Data was gathered at the location level rather than brand level, capturing geographic and contextual variations that national brand-level studies miss.
Control Category Framework
Every citation source was derived from asking each model four types of questions based on our Location-context framework.
| Control Level | Definition | Examples |
|---|---|---|
| Full Control | Content entirely created and hosted by the business | Official websites, owned blogs, corporate newsrooms |
| Some Control | Third-party platforms where the brand can manage its profile | Google Business Profile, MapQuest, TripAdvisor, Zocdoc |
| Limited Control | User-generated platforms with brand participation | Google Reviews, Yelp, Facebook, social media |
| No Control | Independent sources without business input | News articles, Reddit, forums, independent publications |
The aggregate breakdown across all citations:
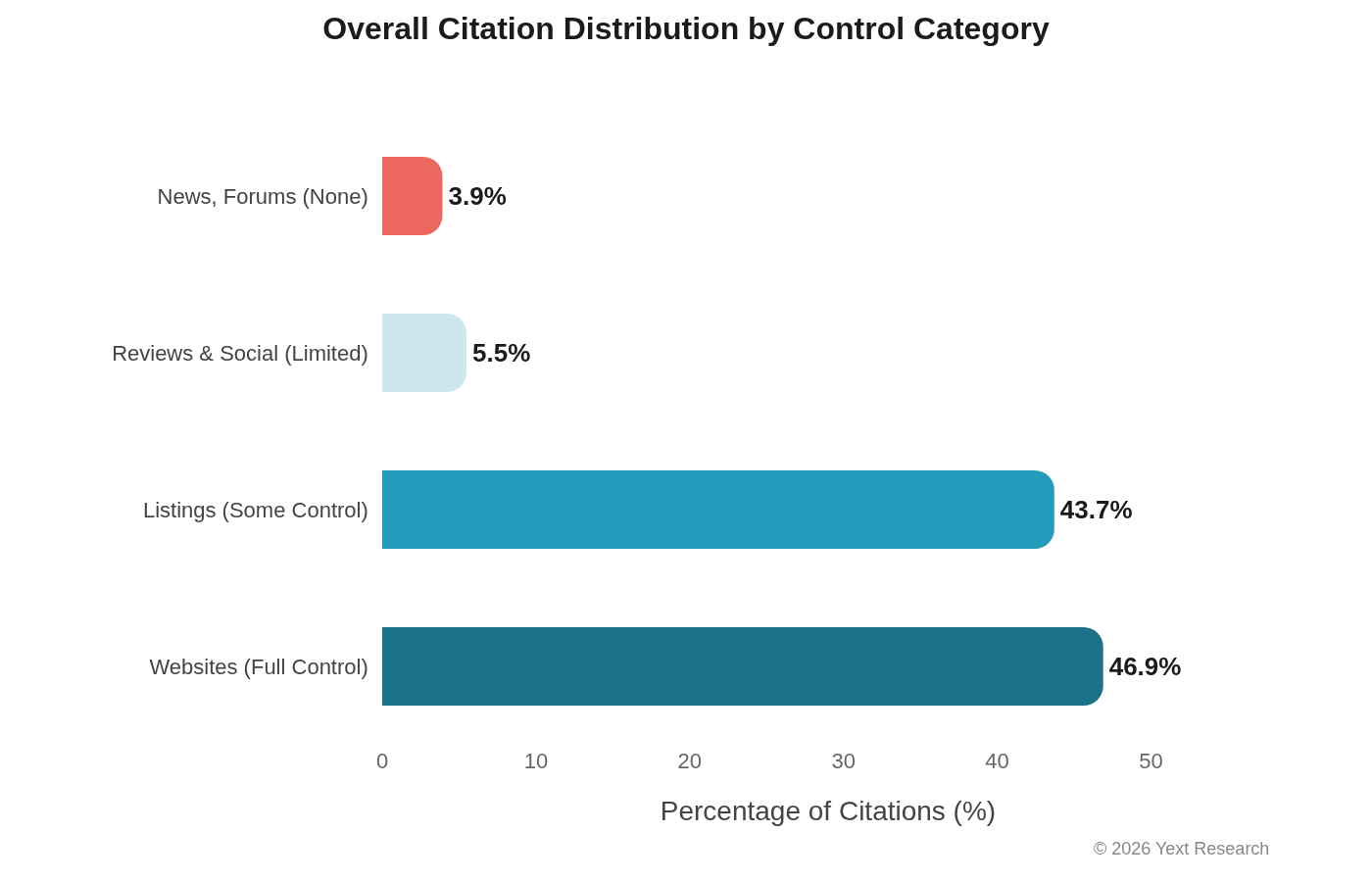
One thing jumps out: Listings represent the largest share of distinct URLs (54.53%), but Websites generate far more citation occurrences per URL (4.31x vs 2.46x). AI models return to first-party content more frequently than they return to any individual listing.
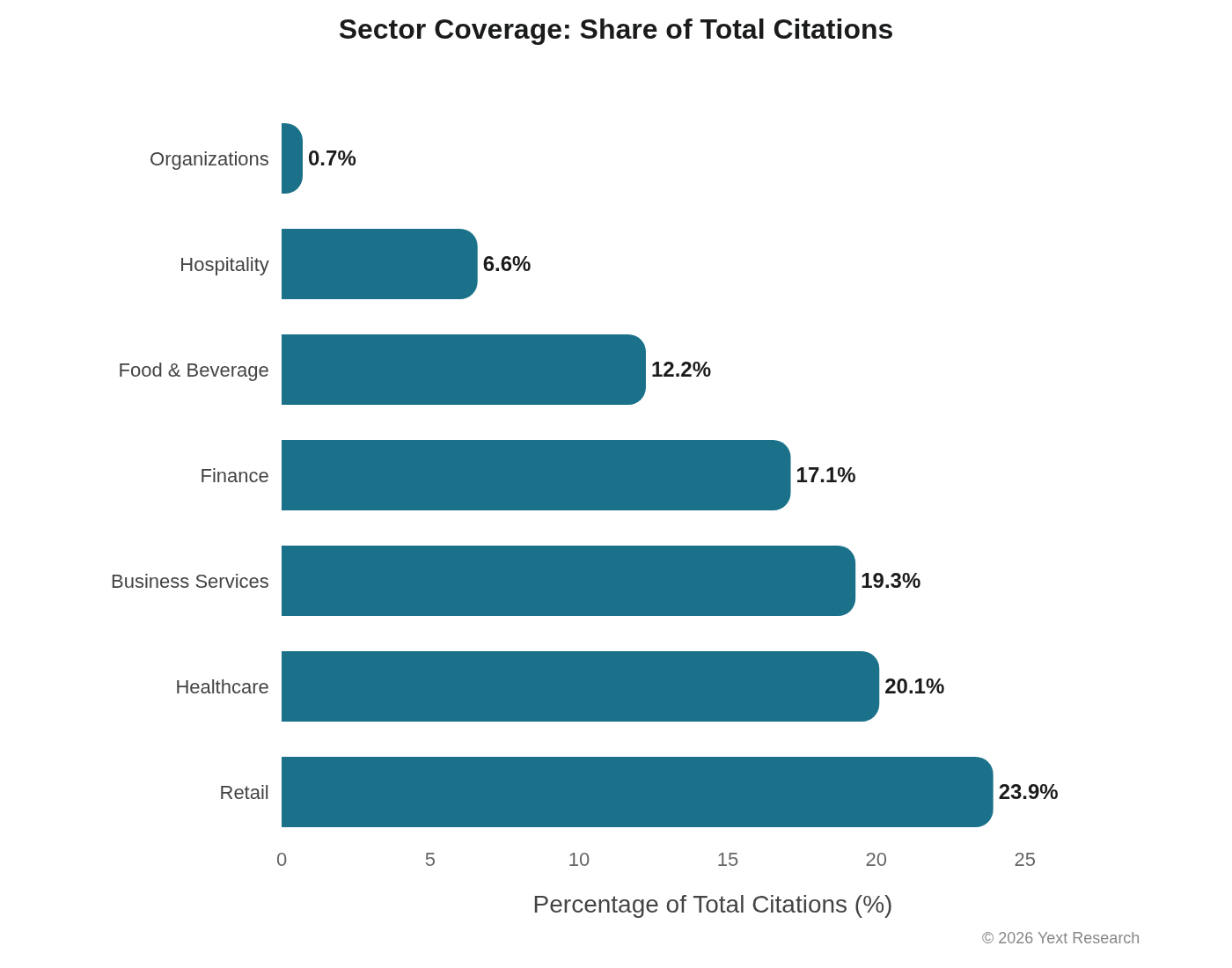
Sector Coverage
The analysis spans seven sectors:
Findings
Exhibit 1: Model-Level Citation Patterns
Each AI model demonstrates consistent citation preferences that persist across industries, though the magnitude varies.
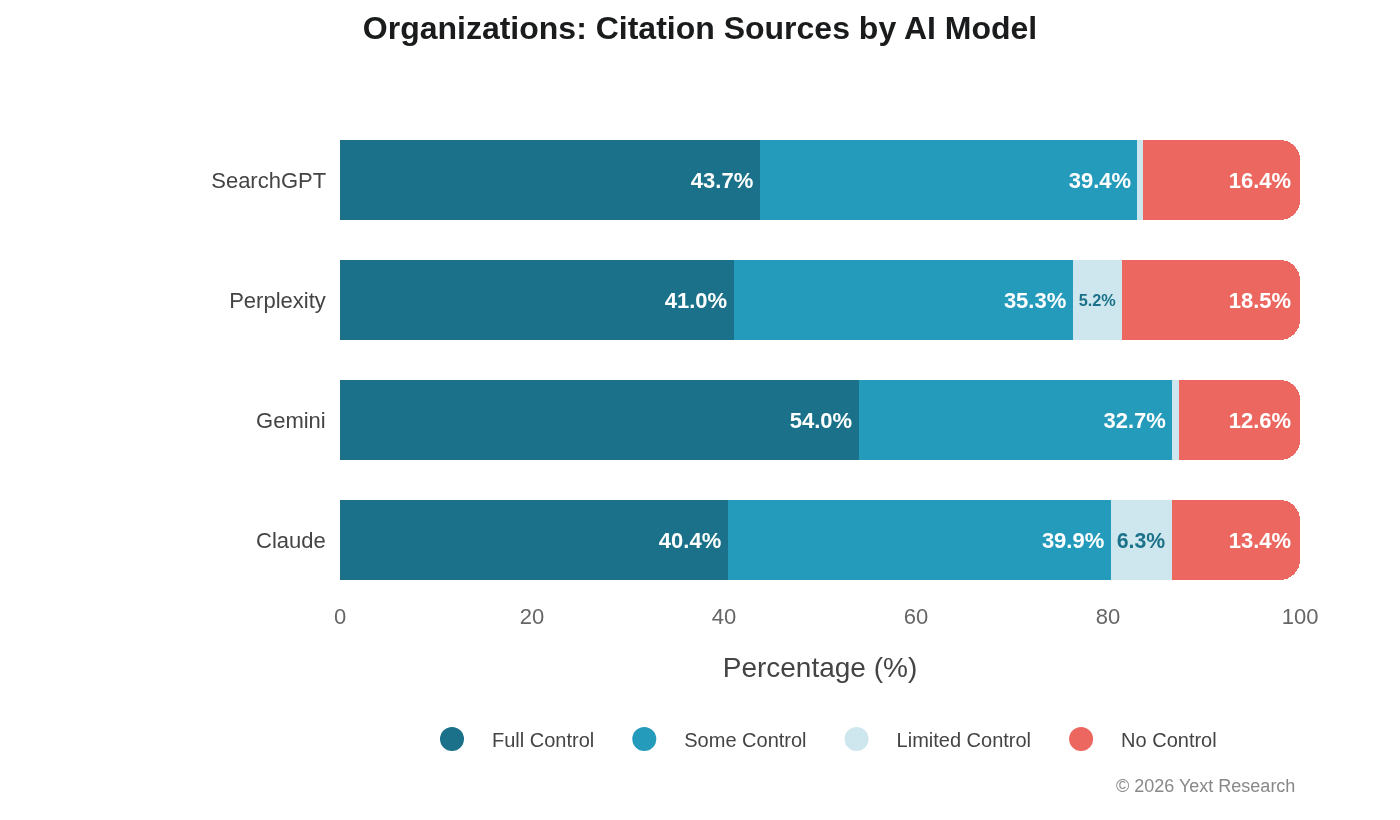
Gemini shows the strongest Full Control preference across most sectors, ranging from 22.4% (Hospitality) to 54.0% (Organizations). This likely reflects Google's integration of E-E-A-T signals into Gemini's citation logic, which we discuss further in the architecture section.
Claude consistently shows elevated Limited Control reliance, ranging from 6.3% (Organizations) to 24.4% (Food & Beverage). This is 2-4x higher than other models in most sectors.
Perplexity demonstrates the most consistent behavior across industries, with Full Control preferences clustering between 37-50% across most sectors. Stability seems baked into its search-first architecture.
SearchGPT shows the highest variance by industry, with Full Control ranging from 28.2% (Food & Beverage) to 43.7% (Organizations), and a notable spike in Hospitality at 38.1%.
Exhibit 2: The SearchGPT Hospitality Anomaly
Hospitality presents the most dramatic model divergence in the dataset:
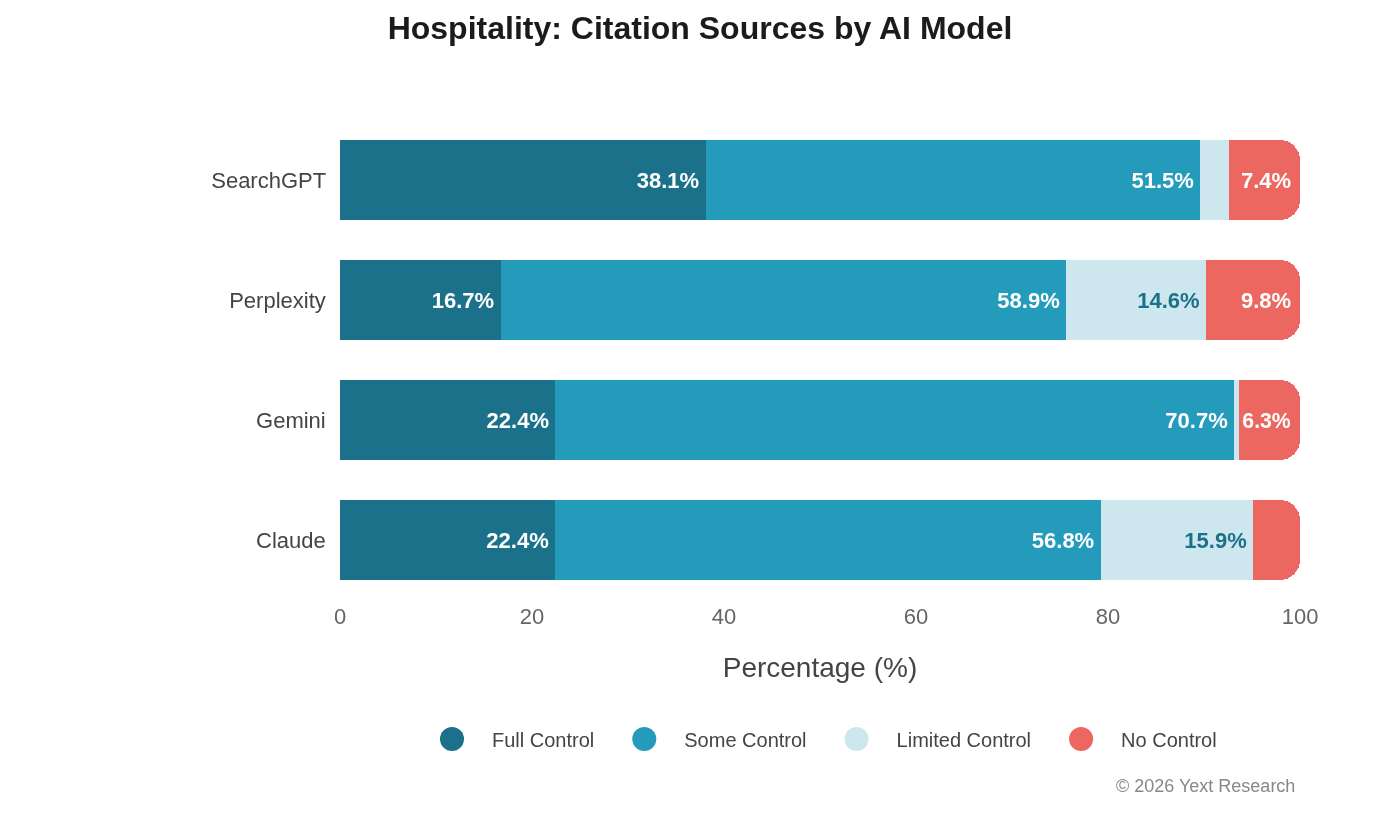
SearchGPT's 38.1% Full Control share is roughly double the rate of other models in this sector. The pattern holds at the industry level within Hospitality.
Industry Breakdown:
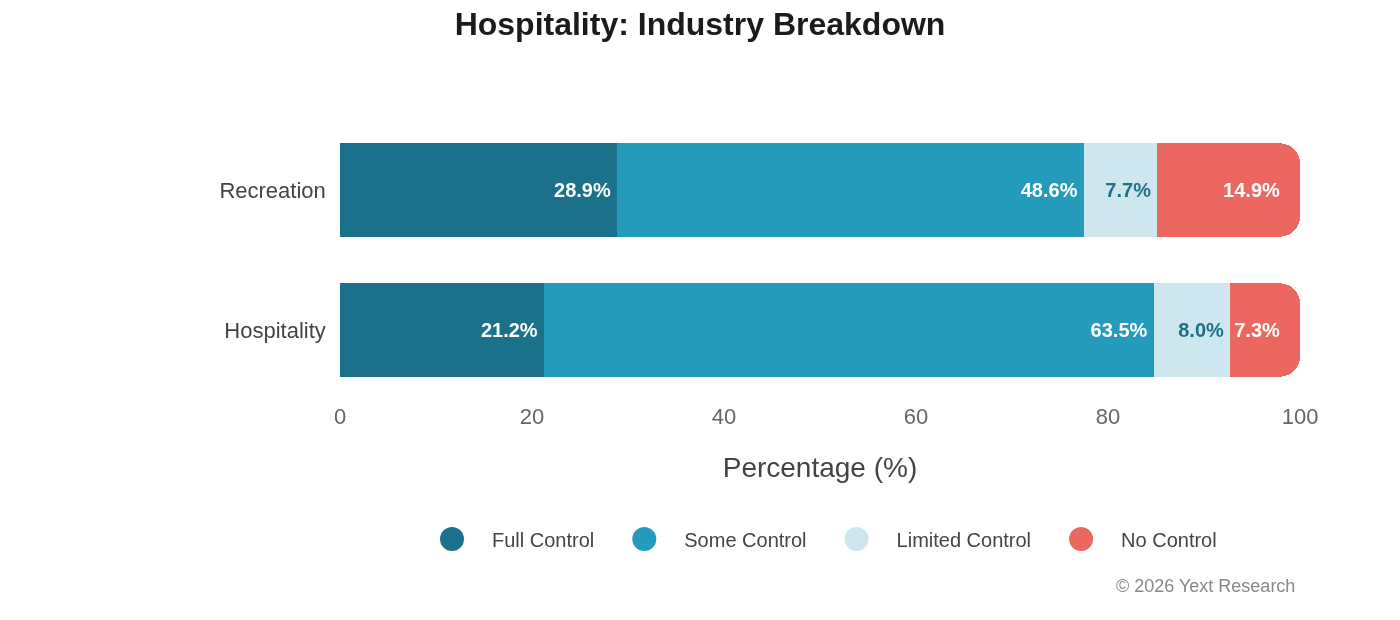
Recreation shows higher Full Control preference (28.9%) and elevated No Control (14.9%), suggesting attractions and activities rely more on independent reviews and travel publications.
Why does SearchGPT favor hotel websites so heavily? The data doesn't tell us. Possible explanations include differences in training data composition, retrieval system configuration, or explicit weighting toward branded sources in travel queries. This is an open question.
Exhibit 3: Business Services
Business Services shows clear model differentiation, with Gemini leading Full Control:
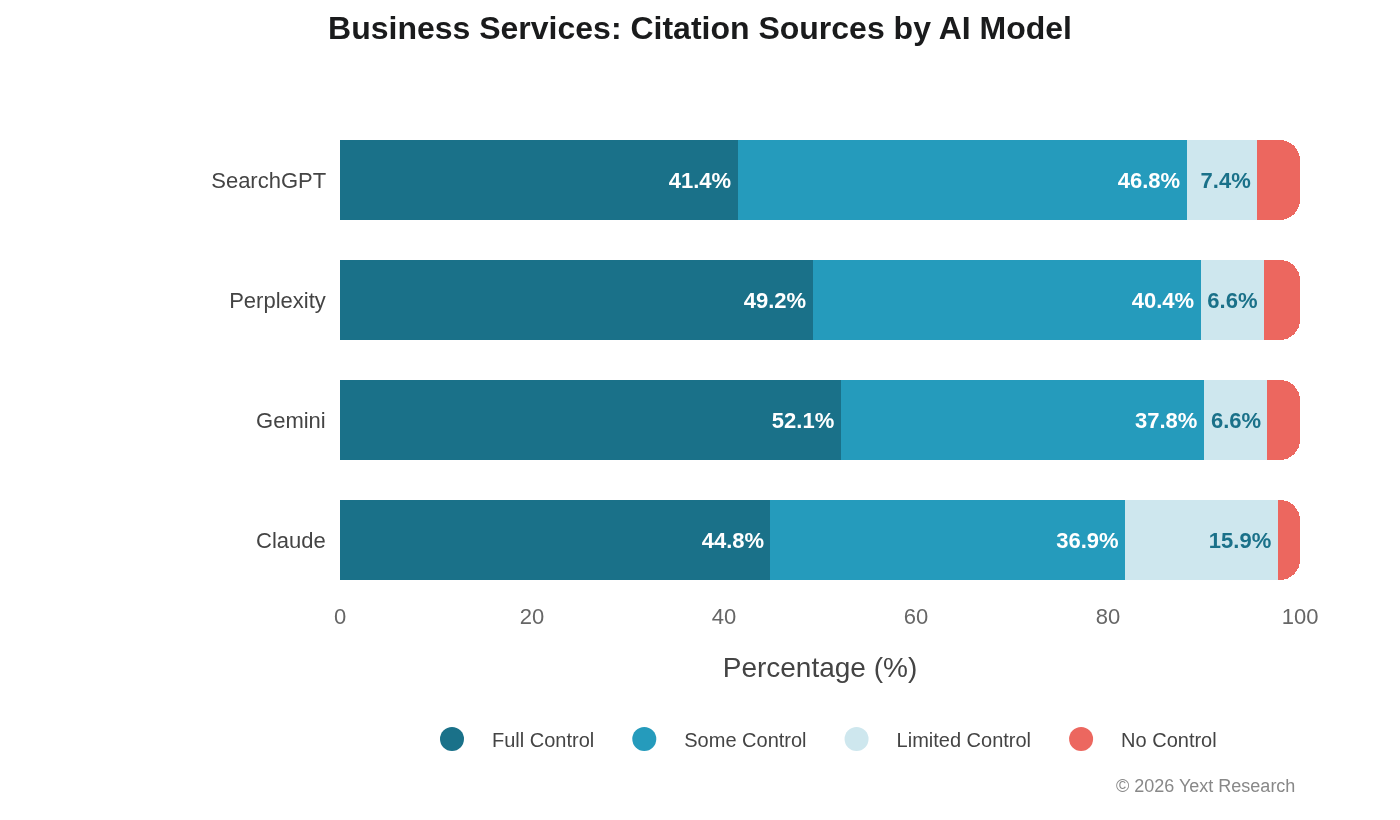
Claude's Limited Control dependency (15.89%) is more than double any other model here.
Industry Breakdown:
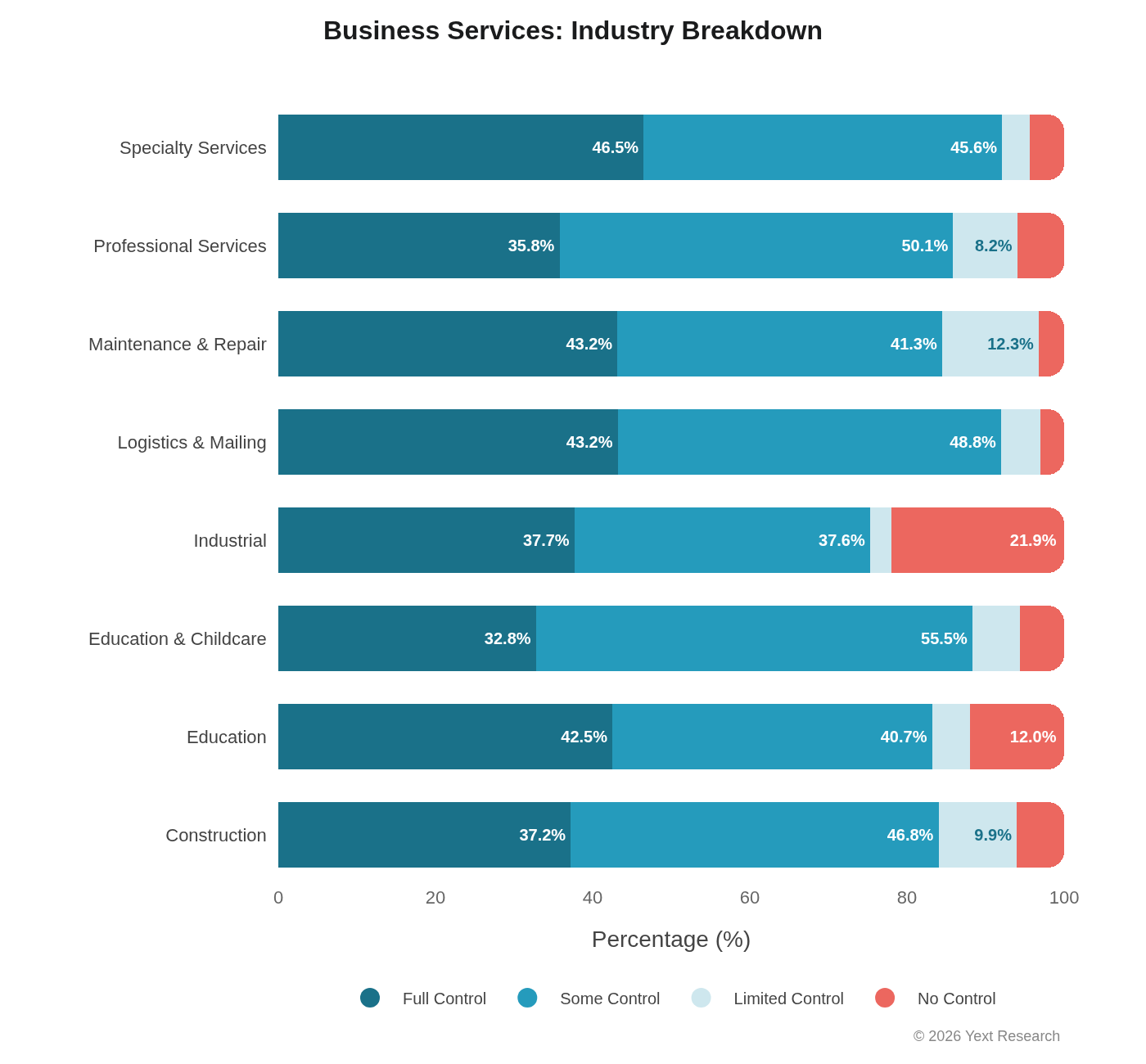
Maintenance & Repair stands out with elevated Limited Control (12.31%), which makes sense: review platforms like Yelp, Angi, and HomeAdvisor are central to how people find plumbers and electricians.
Exhibit 4: Finance
Finance shows strong Some Control preference across models, driven by financial directories and comparison platforms:
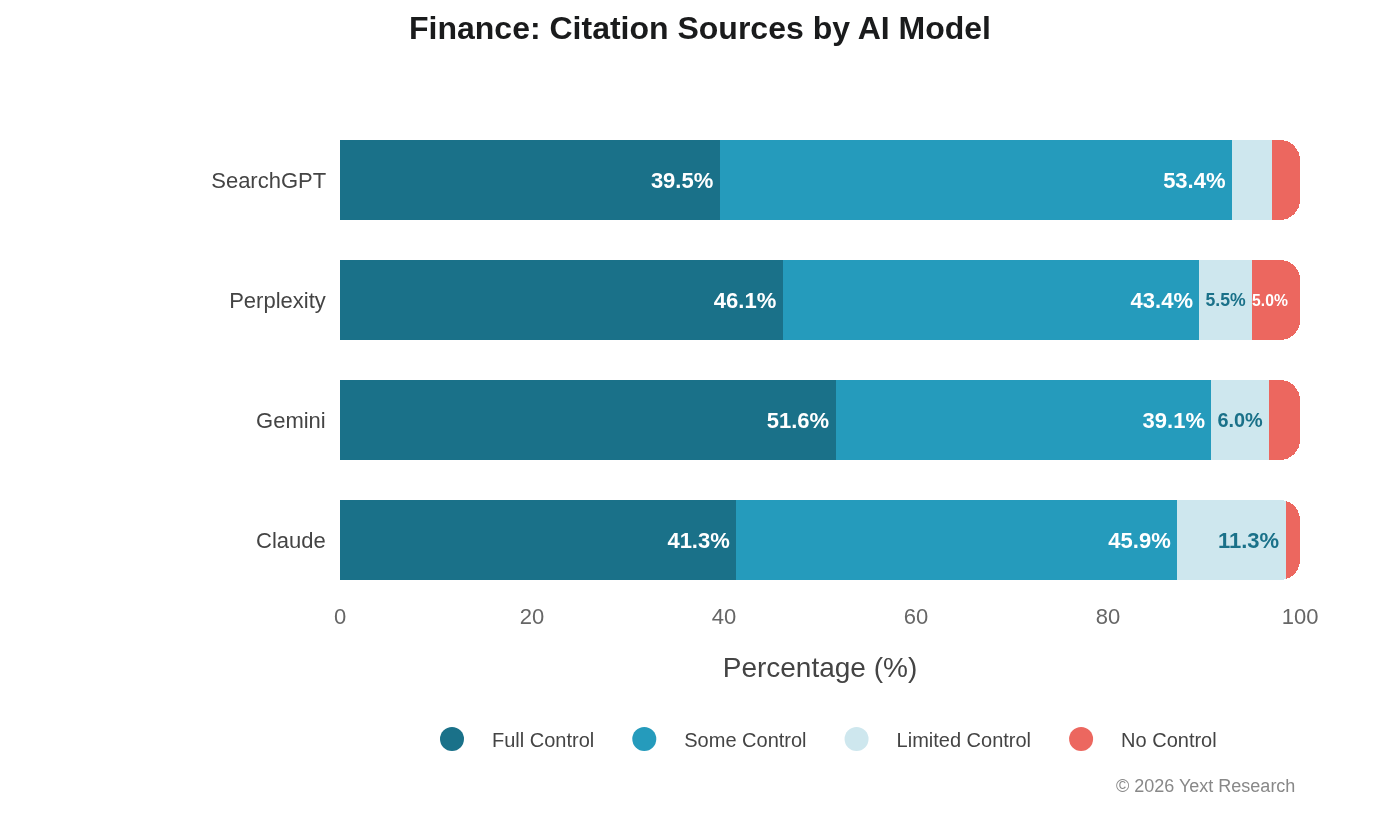
Gemini's 51.62% Full Control share is the highest in this sector, consistent with its general preference for authoritative first-party sources.
Industry Breakdown:
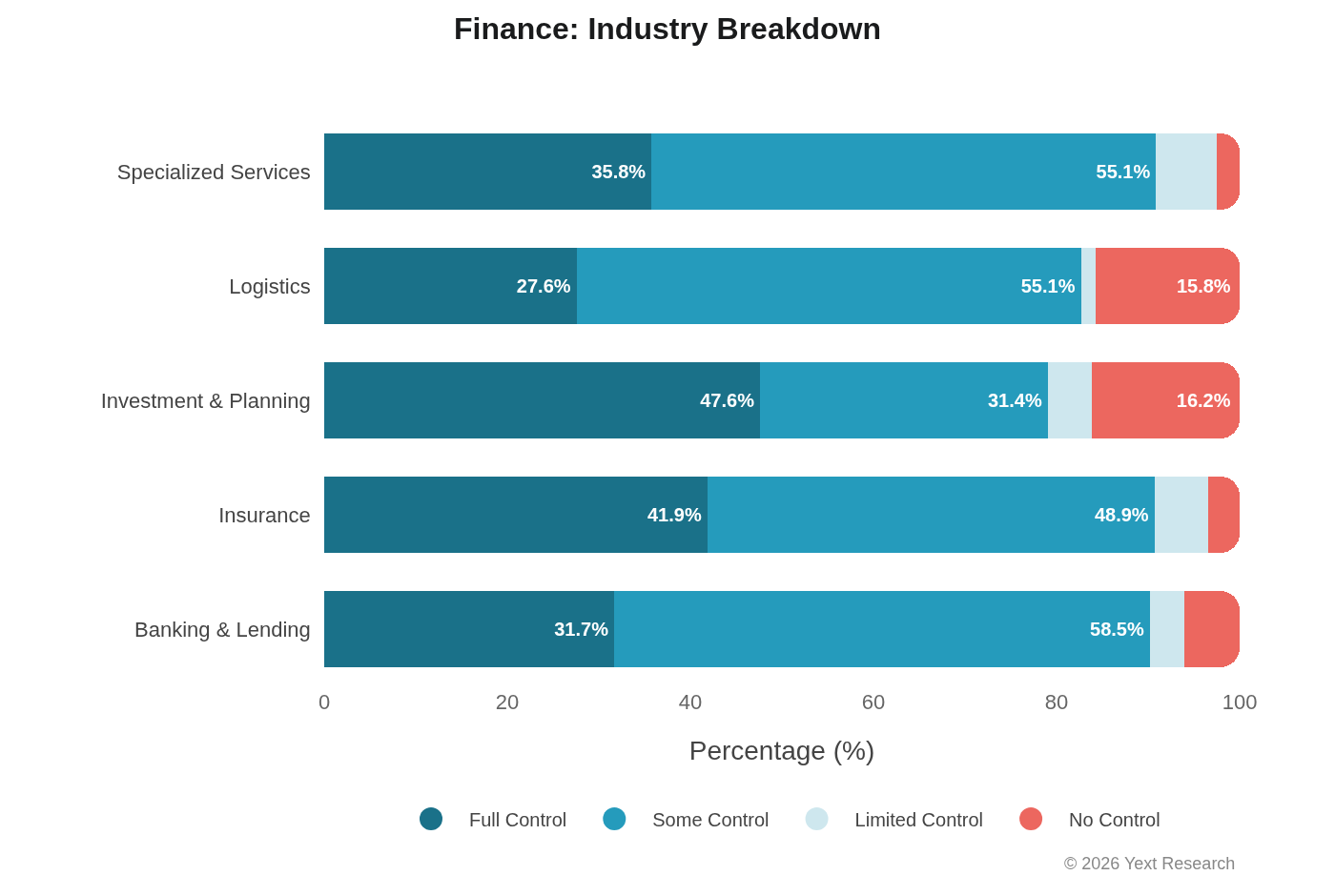
Banking & Lending shows the strongest Some Control preference (58.52%), indicating heavy reliance on financial directories and comparison sites. Investment & Planning and Logistics show elevated No Control (16.19% and 15.78%), suggesting greater reliance on news and independent financial publications. (Note: Investment & Planning has only 315 URLs, so interpret with caution.)
Exhibit 5: Healthcare
Healthcare shows the narrowest model divergence of any sector:
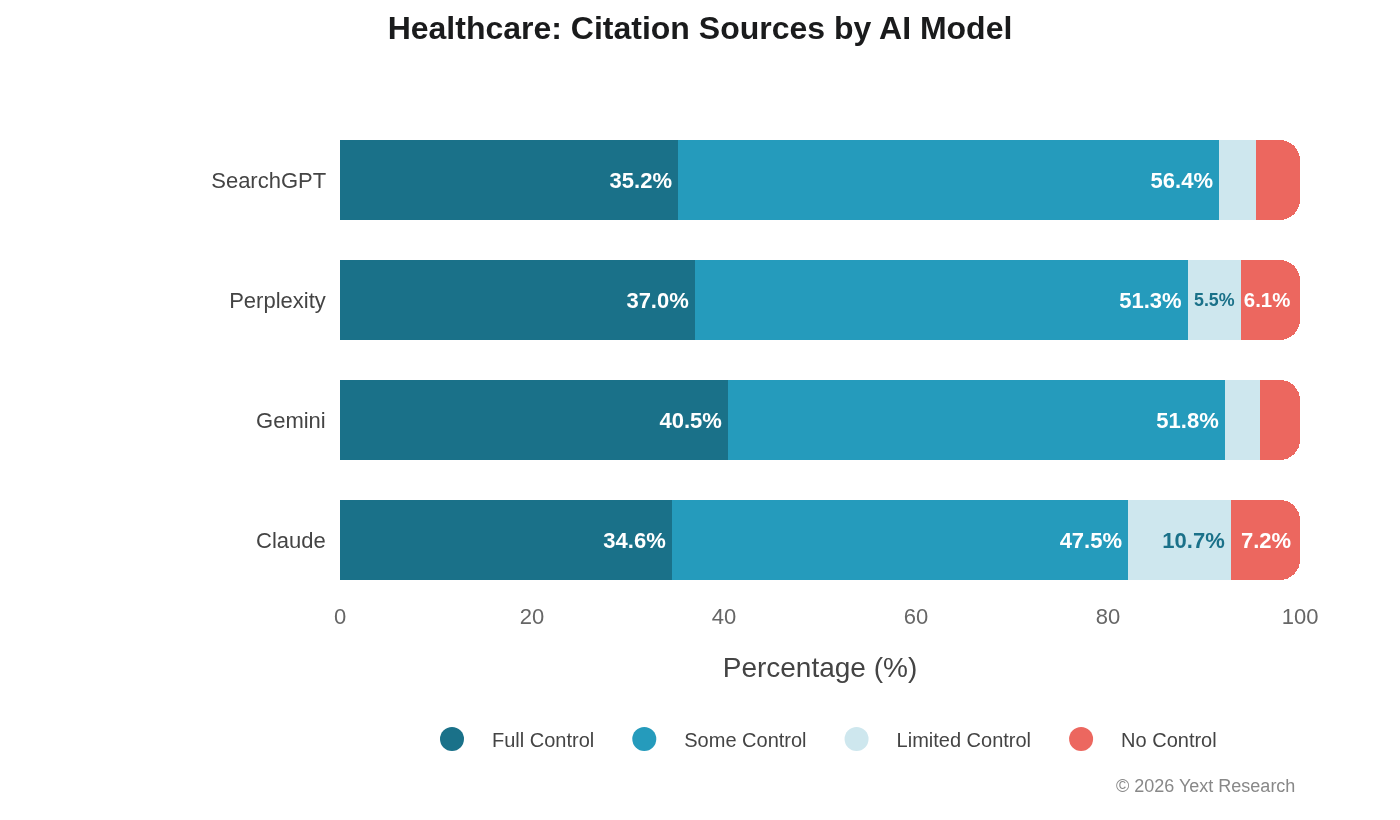
Full Control ranges from 34.60% (Claude) to 40.45% (Gemini), a span of less than 6 percentage points. That's tight. In most other sectors, the spread is 10-15+ points. All four models seem to converge toward authoritative, directory-heavy citation behavior when the topic is medical.
This convergence is worth noting precisely because it's unusual. It may reflect shared sensitivity to medical information accuracy across different model architectures, or it may reflect the structure of available medical sources (dominated by large directory platforms like Zocdoc and Healthgrades). Probably both.
Industry Breakdown:
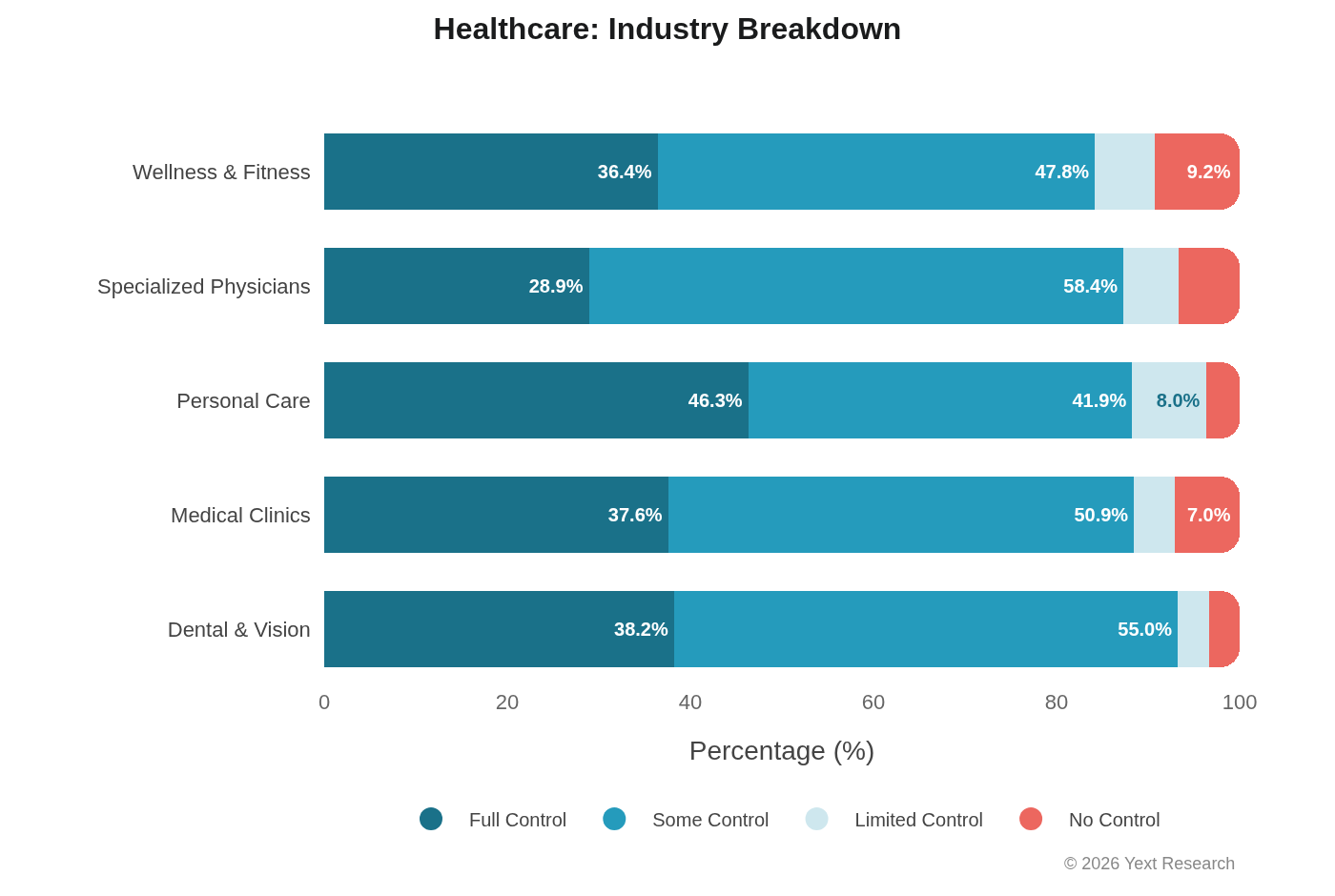
Specialized Physicians show the highest Some Control (58.39%), indicating the centrality of healthcare directories for specialist discovery.
Exhibit 6: Food & Beverage
Food & Beverage is where Claude's Limited Control dependency is most pronounced:
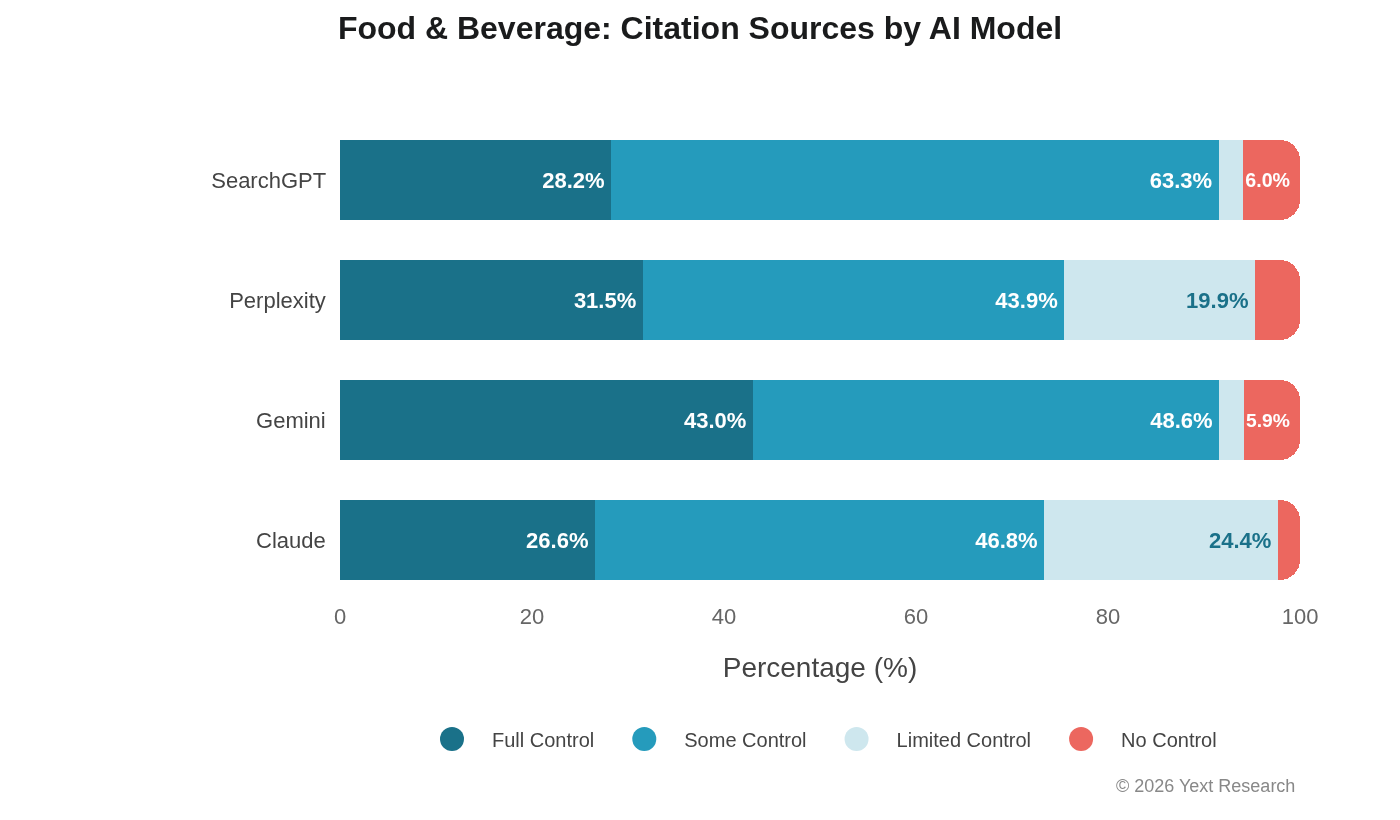
Claude's 24.35% Limited Control share is nearly 10x higher than Gemini's 2.57%. Ask Claude about a restaurant, and roughly one in four of its cited sources will be a review or social media post. Ask Gemini the same question, and that ratio drops to one in forty.
Industry Breakdown:
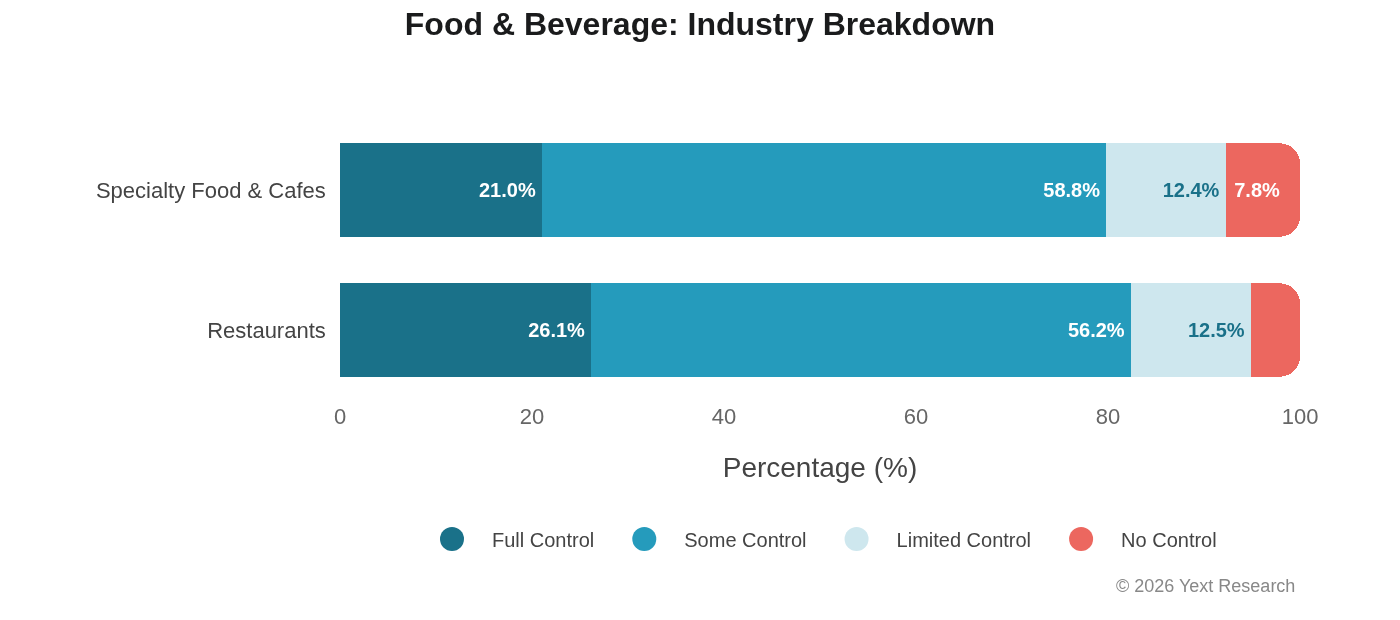
Both industries show similar Limited Control levels (~12.5%), but Specialty Food & Cafes has lower Full Control (21.03% vs 26.15%) and higher No Control (7.75% vs 5.12%), indicating greater reliance on food blogs and independent reviews.
Exhibit 7: Retail
Retail shows moderate variation across models with relatively balanced citation distribution:
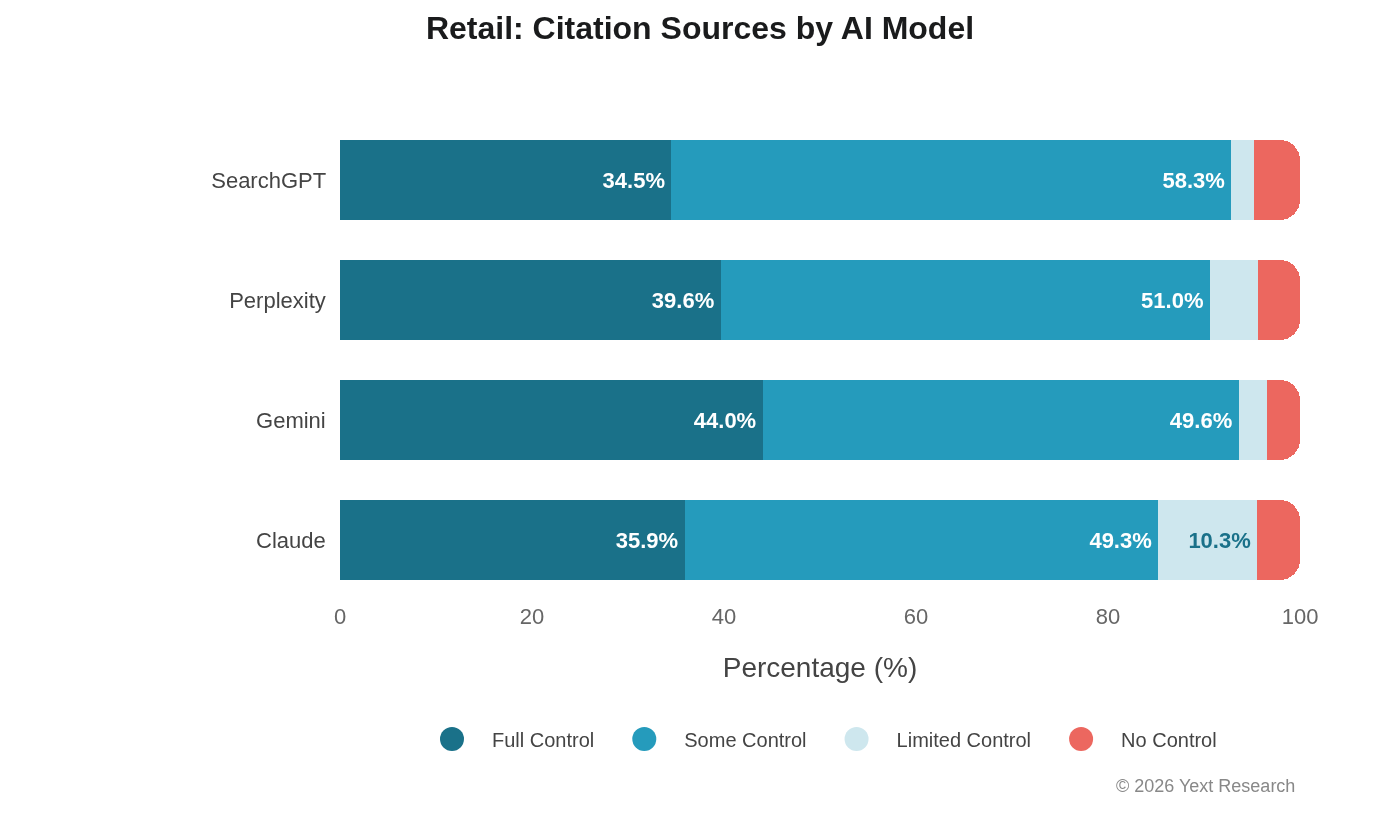
Industry Breakdown:
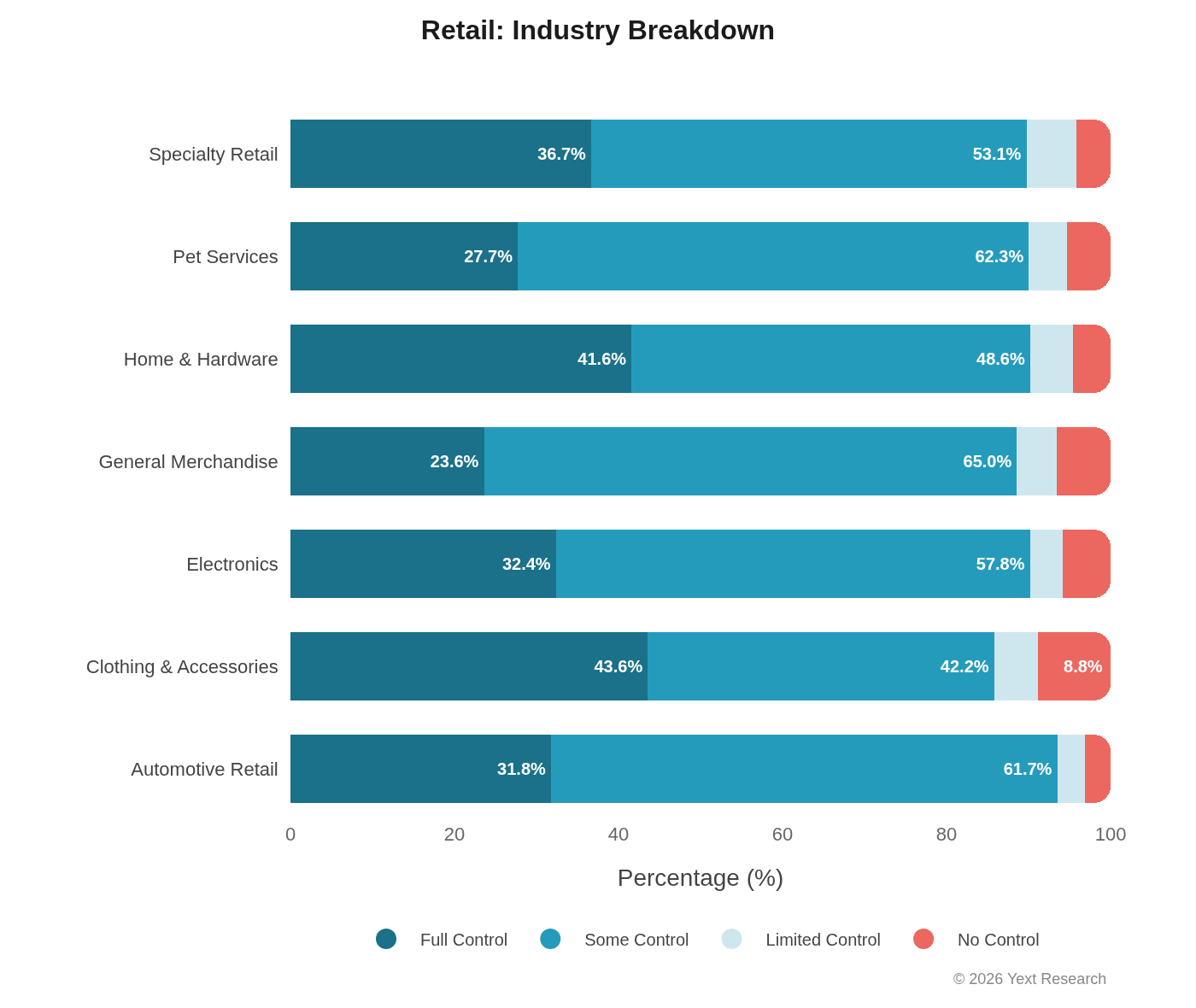
General Merchandise shows the highest Some Control (64.99%) and lowest Full Control (23.60%), suggesting heavy reliance on aggregators and comparison sites. Clothing & Accessories has the highest No Control (8.82%), likely reflecting the influence of fashion publications and style blogs.
Exhibit 8: Organizations
Organizations (non-profits and religious institutions) show uniquely high No Control rates:
No Control ranges from 12.58% (Gemini) to 18.53% (Perplexity), far higher than other sectors. This makes intuitive sense: non-profits and religious organizations are written about in news coverage and community publications more than they produce their own discoverable content.
Industry Breakdown:
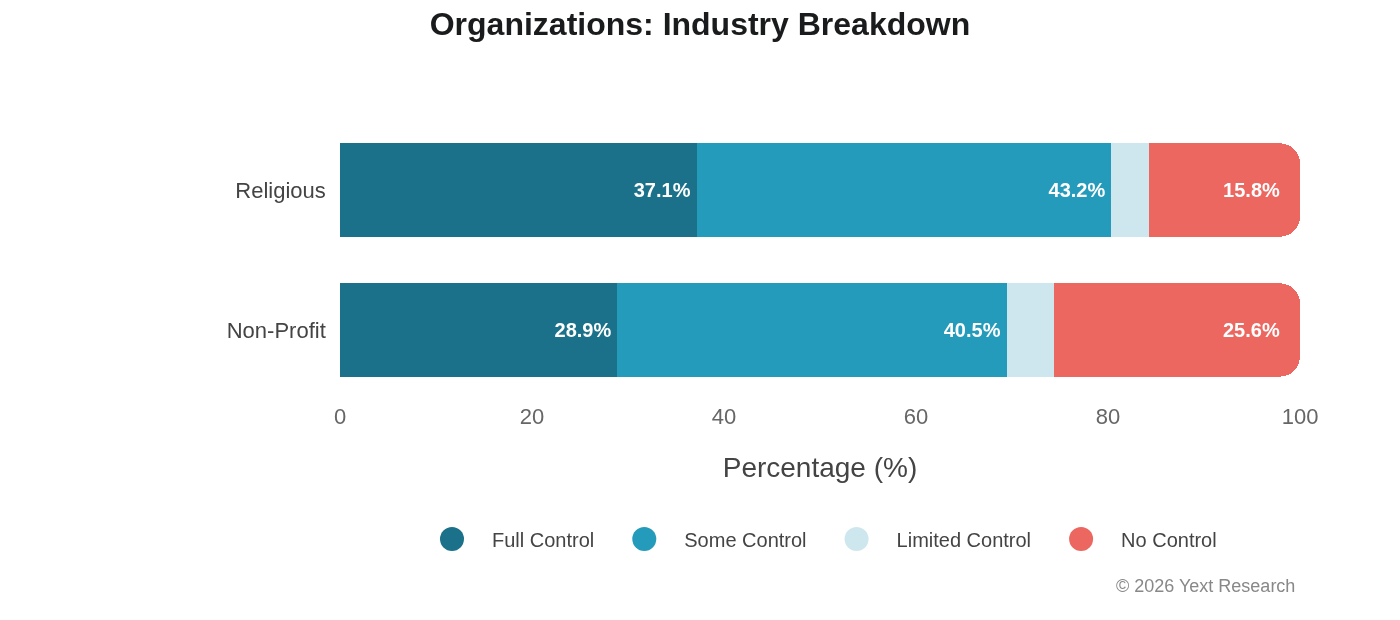
Non-profits show a remarkable 25.62% No Control rate. For these organizations, visibility in AI search is substantially determined by what others write about them.
Exhibit 9: Claude's Limited Control Dependency
Claude's elevated Limited Control reliance is the most consistent cross-sector pattern in the data:
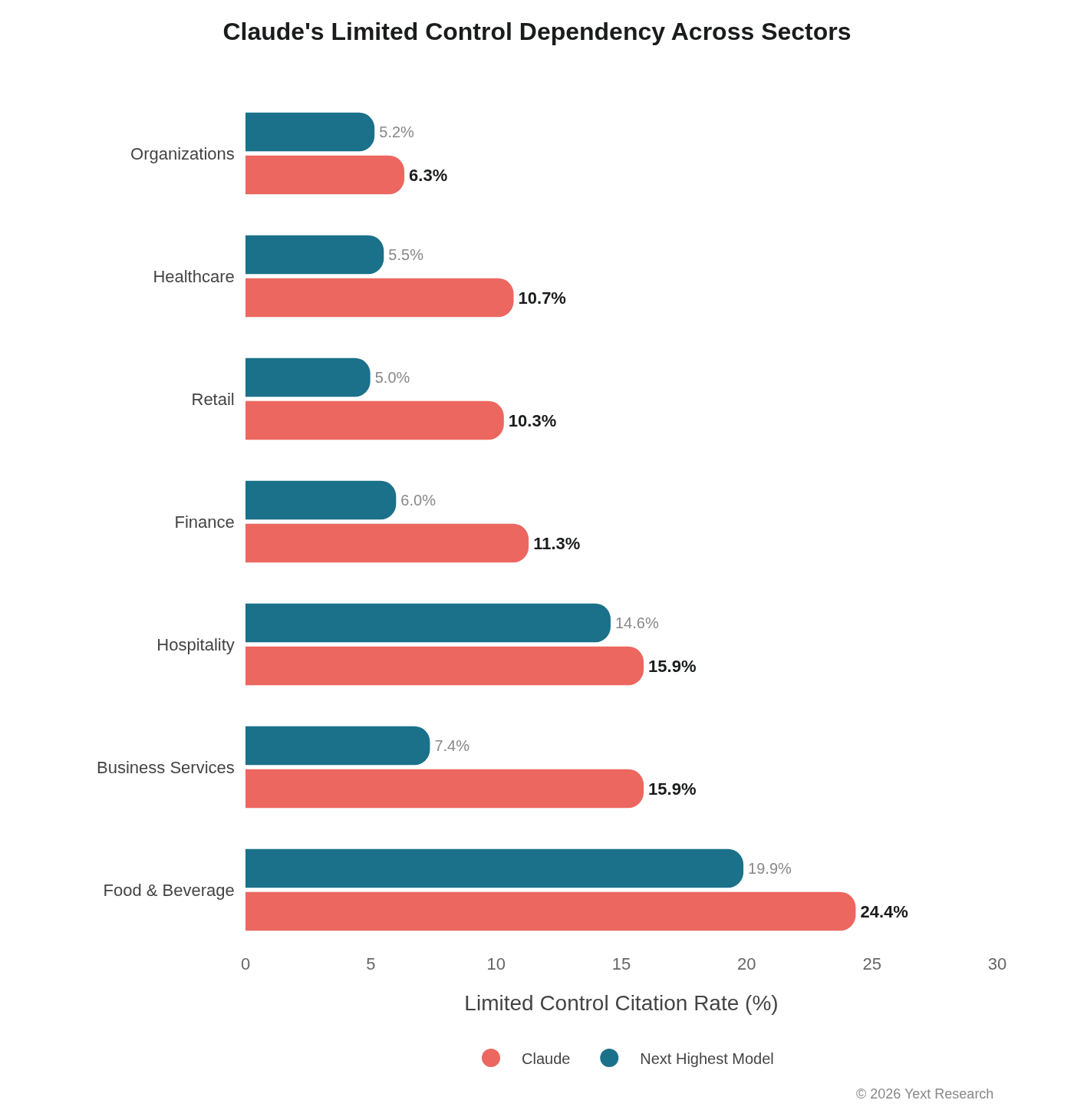
In all seven sectors, Claude leads Limited Control citation share. No other model shows this kind of directional consistency on any single metric.
Exhibit 10: Sector-Level Summary
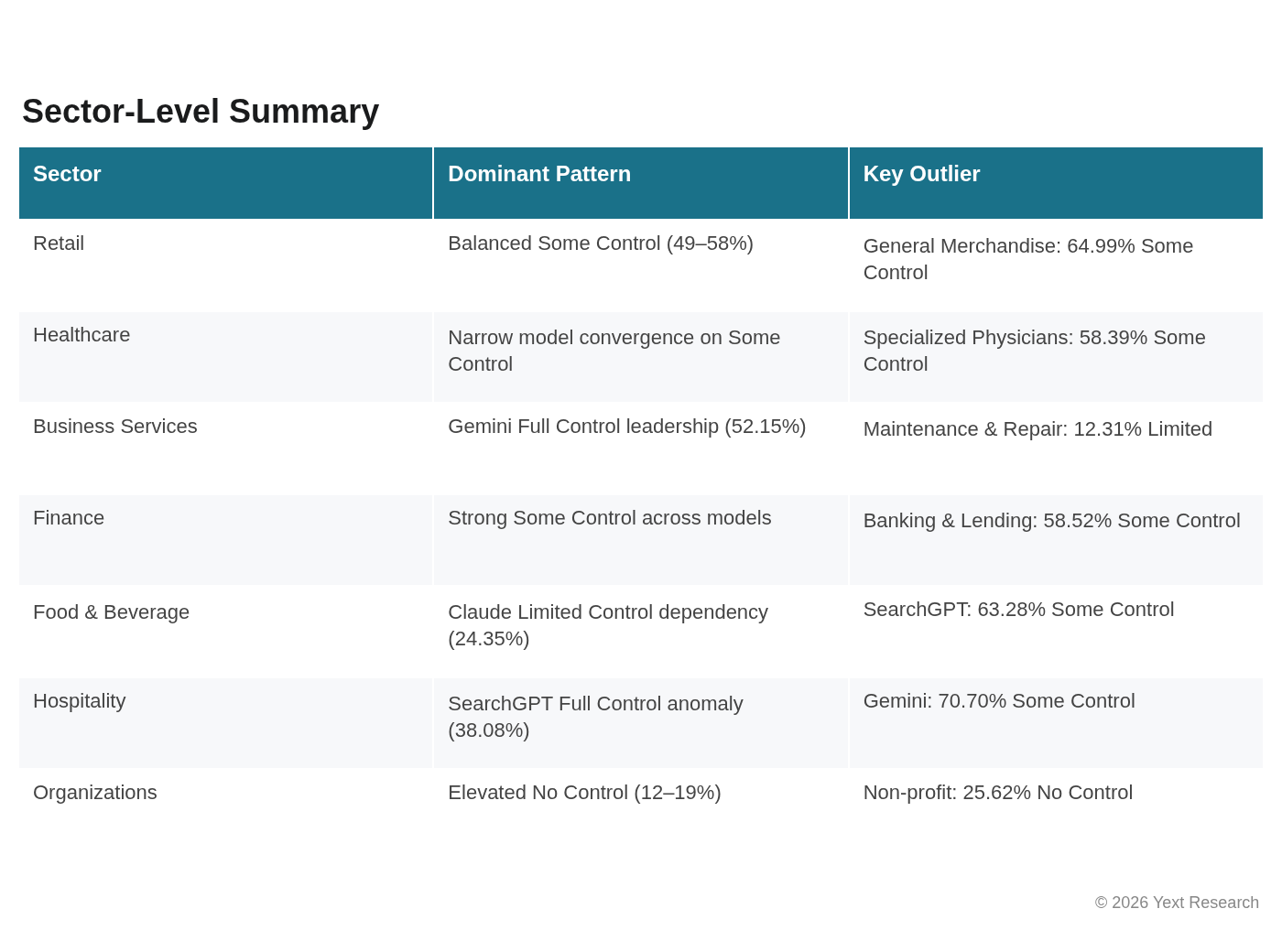
Discussion
Model Architecture and Citation Behavior
The citation patterns in this study aren't random, and they aren't purely editorial choices by the models. They reflect how each model's architecture retrieves and evaluates sources. Understanding those differences helps explain what we observe.
Perplexity (Search-First RAG): Perplexity functions as a search engine, triggering a web search against its own index for each query. Most responses lean heavily on "answer-worthy passages" that can be directly cited. This architecture explains Perplexity's consistency across industries. The retrieval system is optimized for stability rather than context-dependent adaptation.
SearchGPT (RAG with External Retrieval): SearchGPT's base model cannot access the web, so it relies on a retrieval layer to fetch results, then synthesizes the responses. There is no published evidence that ChatGPT internally scores domains by trust, authority, or E-E-A-T. Any such behavior reflects the upstream retrieval system rather than the model itself. This may explain the high industry variance we observe. Citation patterns depend heavily on how the retrieval layer is configured for different query types.
Gemini (Search-Grounded): Gemini is search-grounded, with citations originating from initial grounding rather than the model's base parameters. The grounding source is Google Search. It follows naturally that citations would inherit the Google ranking system. Gemini is an LLM synthesis of Google Search, which means competing for visibility in Gemini still requires excelling at traditional search optimization.
Claude (Constitutional AI): Claude uses RAG like other models, but differs in how it evaluates citation quality. What sets Claude apart is Constitutional AI, a method in which a written set of principles guides training and evaluation. The model critiques and revises its own outputs against a constitution rather than relying solely on human preference rankings. This affects how Claude evaluates answer quality, safety, and completeness, but it does not introduce a distinct citation-ranking algorithm. Claude's elevated Limited Control preference may reflect constitutional principles that weight diverse, user-validated sources as signals of real-world relevance. Or it may simply be an artifact of training data composition. The data can't distinguish between these explanations.
Limitations
This analysis has several limitations worth stating plainly:
-
Correlation, not causation. The data describes citation behavior but does not explain why models cite differently. The architecture discussion above offers plausible explanations, not confirmed ones.
-
Temporal snapshot. This data represents Q4 2025. Model updates happen frequently and may alter citation patterns. We don't know how stable these patterns are over time.
-
Geographic skew. Although data were collected globally, the majority of queries were U.S.-based. International markets may show different patterns.
-
Classification judgment calls. Source categorization required judgment. Edge cases (franchise websites, aggregator reviews) might be classified differently by other researchers.
-
Small sample sizes in some industries. Investment & Planning (315 URLs), Specialty Services (114 URLs), and Industrial (2,677 URLs) are too small to draw confident conclusions from individually.
Areas for Further Research
-
Temporal stability. Do these patterns persist through model updates, or are they transient? Longitudinal tracking would answer this.
-
Consumer impact. How do citation source types affect actual purchase decisions? The link between citation visibility and consumer behavior remains unestablished.
-
International variation. Do these patterns hold outside the U.S.? Regulatory environments and source availability differ by region.
-
Model selection effects. Do consumers with different information-seeking preferences gravitate toward models whose citation behavior matches their needs? This is a testable hypothesis we haven't tested yet.
Conclusion
The simple version of the story: AI models don't all cite the same way, and the differences are large enough to matter for brand visibility.
Gemini favors first-party websites, consistent with its Google Search grounding. Claude draws from user-generated content at rates 2-4x higher than competitors. SearchGPT varies dramatically by industry, with an outsized preference for official hotel sites. Perplexity is the most consistent across sectors.
These patterns also vary more within sectors than across them. A brand in Banking & Lending faces a different citation environment than one in Insurance, even though both sit in Finance.
What we can't yet say is how durable these patterns are, or how directly they translate into consumer decisions. Model architectures change. Retrieval systems get updated. The patterns we measured in Q4 2025 may look different by mid-2026.
What seems less likely to change is the underlying dynamic: different models, different source preferences, different visibility outcomes. Businesses that treat AI search as a single channel to optimize are making an assumption the data doesn't support.
Appendix
Control Category Definitions
| Category | Full Definition |
|---|---|
| Full Control | Content entirely created and hosted by the business. Includes official websites, owned blogs, corporate newsrooms, and first-party landing pages. Brands have complete editorial control over messaging, accuracy, and presentation. |
| Some Control | Third-party directories and platforms where a brand can claim and manage its profile. While the brand does not own the platform, it can directly control the accuracy of its information. Includes Google Business Profile, MapQuest, and industry-specific directories. |
| Limited Control | Platforms where content is primarily user-generated, but brands can actively participate through responses, engagement, and reputation management. Includes Google Reviews, Yelp, Facebook, and social media platforms. |
| No Control | Sources where a brand has no direct control over content. Includes news articles, Reddit discussions, forum posts, user-generated content, and independent publications. |
Past Work
This analysis builds on research from Yext's AI Citations and AI Search Archetypes studies:
- AI Citations, User Locations, & Query Context
- Best Practices Will Only Take You So Far
- The Rise of AI Search Archetypes
About Yext Research
Yext Research conducts independent analysis of AI citation behavior using the Yext Scout platform. Consumer behavior data is gathered through a partnership with Researchscape International.